▲ 核心框架:传统的TCR克隆型(Exact Clonotype)分析因个体间TCR序列的高度多样性而难以在群体中复现。本研究提出的“元克隆型”(Meta-clonotype)框架,以一个抗原富集的TCR为中心(Centroid),定义一个基于生化距离(TCRdist)的半径(Radius),并将该半径内所有生化性质相似的TCR归为一类。这极大地提高了检测的灵敏度和在人群中的可复现性。
🔬 T细胞受体(TCR)由于TCR基因重排的随机性和巨大的序列空间,即使面对相同的抗原,不同个体产生的TCR序列也千差万别。这种“私有性”使得寻找能在群体中通用的TCR生物标志物变得异常困难。近日,由Fred Hutchinson癌症研究中心和St. Jude儿童研究医院领衔的国际团队在顶级期刊《eLife》上发表了一项开创性工作。他们提出了“TCR元克隆型”(TCR Meta-clonotype)这一革命性概念,并开发了配套的开源软件tcrdist3。通过将具有生化相似性的TCR聚集成簇,该方法成功地从新冠患者的TCR数据中鉴定出大量与特定HLA等位基因强相关的公共元克隆型。这项研究不仅为TCR生物标志物的开发提供了全新的范式,也为理解T细胞应答的共性规律打开了新的大门。
T细胞受体(TCRs)编码具有临床价值的信息,这些信息反映了既往抗原暴露情况及潜在的未来免疫应答。然而,尽管深度库测序技术取得进展,TCR的巨大多样性仍使TCR克隆型作为临床生物标志物的应用复杂化。我们提出一种新框架,该框架利用实验推断的抗原相关TCRs形成元克隆型——即生化相似的TCR群组——可用于稳健量化个体间批量库中功能相似的TCRs。我们将该框架应用于COVID-19患者TCR数据,从SARS-CoV-2抗原相关TCRs中生成1831个公共TCR元克隆型,这些TCR具有明确证据表明其仅限于特定人类白细胞抗原(HLA)基因型患者。在独立队列中应用时,与精确氨基酸匹配相比,靶向这些特异性表位的元克隆型在批量库中被检测到的频率更高,且59.7%(1093/1831)在表达推定限制性HLA等位基因的COVID-19患者中更为丰富(错误发现率[FDR]<0.01),这证明了元克隆型作为生物标志物开发中抗原特异性特征的潜在应用价值。为促进进一步应用,我们开发了开源软件包tcrdist3,该软件实现了此框架并支持基于距离的TCR库分析的灵活工作流程。
个体独特的T细胞受体(TCR)库由抗原暴露塑造,是免疫记忆的关键组成部分。随着免疫库分析技术的进步,TCR库已成为一个尚未充分开发的生物标志物来源,可用于预测对多种暴露的免疫反应,包括病毒感染、肿瘤新抗原或环境过敏原。
然而,TCR库在个体内部和个体之间表现出的极端多样性,给生物标志物开发带来了重大挑战。通过肽段-主要组织相容性复合体(pMHC)四聚体分选技术聚焦于识别特定表位的TCR(该方法依赖于已知的肽抗原及其MHC限制性),通常发现许多不同的TCR能够识别单一pMHC。这使得抗原暴露的群体特征检测变得复杂。建模研究(Elhanati等,2018)和实证证据(Soto等,2019)表明,仅10%-15%的单链TCR是公共或被多个个体共享的。此外,由于仅能对部分T细胞受体(TCR)库进行采样,这使得从个体中可重复检测相关TCR克隆型变得困难,更不用说在群体中可靠地检测公共克隆型了。
实际上,异质性库测序深度会加剧这一问题,因为它会影响对罕见TCR频率的估计精度。因此,目前单个T细胞克隆型在群体水平的TCR特异性研究中仍存在不足,其统计效力不足,这限制了它们在基于TCR的临床生物标志物开发中的应用。
本研究提出了一种构建“元克隆型”的框架:通过将具有生化相似互补决定区(CDRs)的TCR进行分组,实现群体水平生物标志物的开发(图1)。此前我们开发的TCRdist是一种基于生化信息的距离度量方法,能够根据序列相似性将配对的 αβ TCR按抗原特异性进行分组(Dash 等,2017)。TCRdist与编辑距离相关,但具有相同编辑距离的TCR间其差异可能显著(图2)。
虽然现有工具可识别单一样本中统计异常的TCR群组(可能提示抗原选择的多克隆反应, Glanville 等,2017; Huang 等,2020; Pogorelyy 等,2019; Pogorelyy 和 Shugay ,2019; Ritvo 等,2018; Shugay 等,2015),但元克隆型框架的开发目标不同:利用体外实验确定的受体-抗原关联,从原本私有的TCR中创建公开的抗原相关元克隆型。这一应用得益于新型开源Python3软件包tcrist3,该软件包为基于距离的库分析提供了灵活性,支持距离度量的定制化,并通过稀疏数据表示和并行化字节编译代码实现大规模计算。
传统TCR分析的困境——“大海捞针”式的精确匹配
在新冠大流行初期,研究人员通过MIRA等技术,从患者体内富集到了大量能识别SARS-CoV-2肽段的TCRβ链序列。这些序列构成了宝贵的“抗原相关TCR”资源。
然而,当研究者试图在独立的、大规模的新冠患者队列(如immuneRACE项目中的694名患者)中寻找这些“精确匹配”的TCR时,却发现它们的检出率极低。这是因为:
- TCR的极端多样性:即使是识别同一抗原的T细胞,其TCR序列也可能存在细微但关键的差异。
- 测序深度限制:高通量测序无法覆盖个体全部的TCR库,稀有的克隆型很容易被遗漏。这种“精确匹配”策略的低灵敏度,严重制约了TCR作为可靠生物标志物的应用。
“元克隆型”框架——用生化相似性代替序列同一性
为了解决上述困境,研究团队提出了一个优雅的解决方案:不再执着于寻找完全相同的TCR序列,而是寻找生化性质相似的TCR家族。
“元克隆型”的构建包含三个核心要素:
通过这个框架,一个原本只在少数个体中出现的“私有”中心TCR,就变成了一个可以在人群中广泛检测到的“公共”元克隆型。
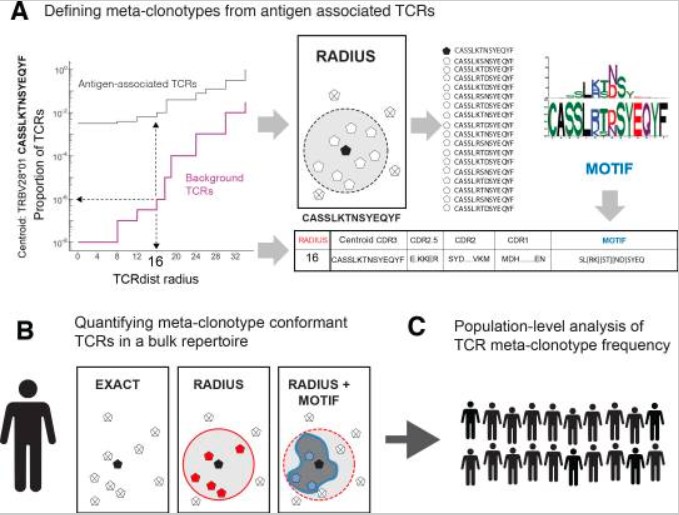
图1:描述了一种用于识别和量化抗原特异性T细胞受体(TCR)的计算方法,称为“meta-clonotype(元克隆型)”构建与分析流程。
图1A-从抗原相关的TCR中定义 meta-clonotypes,目标是不仅只关注单个TCR,而是想找出一群在生化特性上相似的TCR,它们可能都能识别同一个抗原——这就是“meta-clonotype”。具体方法是:使用一个叫 tcrdist3 的工具,计算每个TCR与其他TCR之间的“距离”(TCRdist),这个距离基于TCR氨基酸序列的相似性(尤其是CDR3区域,这是识别抗原的关键部位)。对于每一个“中心TCR”(centroid TCR),尝试不同的“半径”(radius),看在这个半径内能包含多少真实的抗原相关TCR(黑色曲线)和合成的背景TCR(紫色曲线)——这些是随机生成的、不针对该抗原的TCR,用来模拟“偶然出现”的情况。
图中展示了一个针对SARS-CoV-2病毒一段肽(ORF1ab 1316–1330)的meta-clonotype,其CDR3β链的保守基序用logo图表示。简单说:meta-clonotype = 一个中心TCR + 一个最大安全半径(排除随机噪音)+ 一个CDR3保守基序,代表一群功能相似的抗原特异性TCR。
图1B:在大量TCR数据中量化符合meta-clonotype的TCR
有了meta-clonotype的定义后,就可以在普通人的TCR测序数据(bulk repertoire)中搜索类似的TCR:
- EXACT:完全匹配中心TCR的氨基酸序列。
- RADIUS-conformant:与中心TCR的距离 ≤ 设定的半径(即使序列不同,但足够相似)。
- RADIUS + MOTIF conformant:不仅距离够近,而且CDR3序列还符合那个保守基序——这是最严格的匹配。
这样就能从海量TCR中找出“可能识别同一抗原”的T细胞,而不仅限于完全相同的克隆。
图1C:在人群水平分析meta-clonotype的频率
研究人员在多个新冠患者的TCR数据中(感染后0–30天采集)搜索这些meta-clonotype。发现:相比只统计“完全相同的TCR克隆”(exact clonotypes),使用meta-clonotype conformant TCR的数量能更好地关联到患者的HLA类型(即MHC分子,决定哪些肽能被呈递给T细胞)。
这说明:meta-clonotype捕捉到了更强的抗原特异性信号,因为它整合了功能相似但序列略有差异的TCR,比单看一个克隆更稳健、更具生物学意义。
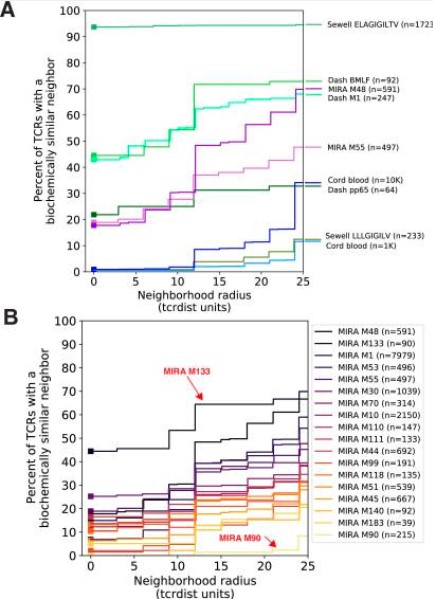
图2A-TCR 数据子集的来源与邻域分析,研究人员使用了三种不同方式获得的TCR子集:
- MHC四聚体分选(绿色):通过肽-MHC四聚体(pMHC tetramer)标记并单细胞分选出能特异性结合某个抗原肽的T细胞。
- 这些TCR是已知抗原特异性的“金标准”,通常高度富集于识别同一表位的克隆。
- MIRA肽刺激富集(紫色):使用MIRA技术(一种高通量抗原筛选方法)对T细胞进行特定病毒肽段(如MIRA55、MIRA48)刺激后,富集响应的TCR。这些TCR也具有抗原反应性,但可能包含更多样化的克隆(不一定完全相同)。
- 脐带血随机抽样(蓝色):从脐带血(代表未经历抗原暴露的“初始”T细胞库)中随机抽取1,000或10,000个TCR。这作为阴性对照,代表普通人群中的随机TCR多样性,基本不含抗原经验。
对每个子集内所有TCR两两计算 TCRdist 距离(一种衡量TCR生化相似性的指标,主要基于CDR3氨基酸序列)。对每个TCR,以其为中心画一个“邻域”(neighborhood),半径为 x 轴所示的 TCRdist 值。
计算该集合中有多少百分比的TCR,其邻域内至少包含另一个TCR(即不是孤立的)。
当半径 = 0 时,只有完全相同的氨基酸序列才算“邻近”——此时的值(实心方块)反映重复克隆的比例(即克隆扩增程度)。曲线越靠左/越高,说明该TCR集合内部越聚集(很多TCR彼此相似);曲线越平缓靠右,说明越分散/多样。
举例:MHC四聚体分选的TCR(绿色)通常在小半径下就有很高覆盖比例,因为它们识别同一表位,序列高度相似;而脐带血(蓝色)则需要很大半径才能让TCR“互相靠近”,说明多样性高、聚集性低。
图2B-对MIRA数据集按HLA等位基因富集情况进行分析
研究人员进一步聚焦于那些MIRA实验中供体显著富集了某个特定I类HLA等位基因的TCR集合。因为TCR识别抗原依赖于HLA呈递,同一HLA类型的人更可能产生相似的TCR应答。图中每条线代表一个这样的MIRA集合(例如MIRA55可能在HLA-A*02:01携带者中富集)。颜色分配依据:按图右侧 y 轴上各曲线的垂直排序位置(即最终覆盖百分比高低)来分配颜色,并与图例顺序一致。这样便于视觉比较:哪些HLA相关的MIRA集合TCR更聚集(曲线更高),哪些更分散。
💡在新冠数据中的成功验证——HLA关联性显著增强
研究团队将这一框架应用于17个具有明确HLA限制性的SARS-CoV-2 MIRA数据集,成功构建了1831个元克隆型。
在对694名独立新冠患者的TCR库进行回溯性分析时,结果令人振奋:
- 检出率大幅提升
元克隆型(无论是仅用半径RADIUS,还是结合基序RADIUS+MOTIF)在患者库中的检出频率远高于精确匹配的克隆型。 - HLA关联性极强
高达59.7%(1093/1831)的元克隆型,在表达其预测限制性HLA等位基因的患者中显著富集(FDR < 0.01)。相比之下,精确匹配克隆型的这一比例不足3.7%。
这些数据雄辩地证明,“元克隆型”作为一种抗原特异性的特征,其作为群体水平生物标志物的效力远超传统的精确匹配策略。
结语:从序列到功能,构建TCR研究的完整闭环
这项发表于eLife的研究,其深远意义在于它巧妙地弥合了计算生物学与实验免疫学之间的鸿沟。“元克隆型”不仅仅是一个计算概念,它背后代表的是T细胞识别抗原时所遵循的生化共性。
然而,任何计算预测都必须经过实验的严格验证。 pMHC多聚体技术作为验证TCR抗原特异性的金标准,在这一流程中扮演着不可替代的角色。
桂芎生物的核心优势,正是在于我们能够提供这样一个完整的闭环: 我们既能利用先进的计算工具帮助您从海量数据中发现潜在的生物标志物信号,又能通过世界一流的pMHC多聚体平台对其进行精准的功能验证。这种“干湿结合”的能力,确保了您的研究发现既具有前瞻性,又具备坚实的实验基础。
选择桂芎,就是选择了高效、可靠、一站式的TCR研究解决方案,共同推动下一代免疫诊断和治疗的发展。
参考文献:TCR meta-clonotypes for biomarker discovery with tcrdist3 enabled identification of public, HLA-restricted clusters of SARS-CoV-2 TCRs. eLife, 2021, 10:e68605.
如何将转化为研究成果?
桂芎生物可提供关键产品支撑:
1. 微量pMHC复合物合成服务: 支持HLA-A*02:01等33种主流HLA等位基因,用于抗原特异性T细胞验证
2 . pMHC荧光四聚体合成以及筛选: 现货覆盖多种肿瘤抗原(如HPV/CMV/EBV/KRAS等),快速分选抗原特异性T细胞
3. 工程化呈递细胞构建: K562-HLA系列,模拟体内抗原呈递,用于DC功能模拟
4. 单克隆TCR测序: 从四聚体阳性T细胞中获取配对链的TCR主克隆
5. 抗原肽-MHC亲和力高通量ELISA扫描服务: 高通量筛选最优表位,指导DC疫苗设计
6. 抗原特异性T细胞扩增: 桂芎拥有稳定的抗原特异性DC的分化成熟工艺,是抗原特异性T细胞扩增和检测的基石。
Views: 23
